Nanosecond IPC: A Lock-Free Shared Memory Broadcast Bus in Rust
Building a lock-free shared memory ring buffer in Rust for sub-100ns IPC — from SPSC to SPMC broadcast, with benchmarks on real hardware.
In the previous post, I chose RocksDB as the embedded database for storing nearly 1 billion Solana key-value pairs. I mentioned that the system must recover gracefully after a crash or restart — here’s why that matters.
The database is fed by remote gRPC streams, which are inherently less reliable than local computation — connections drop, providers go down, slots get skipped. If the DB runs as a child component inside the main application, a crash in any part of the app takes everything down: the gRPC connection, the database state, and every downstream consumer. Restarting means re-establishing the stream, re-validating state, and potentially re-bootstrapping — all while downstream processes are blind.
By running the database as a separate process, failures are isolated. The gRPC ingestion process can crash and restart without corrupting the database. The database process can restart and resume from its last committed state without affecting downstream consumers. Each component has its own lifecycle — deploy, restart, and debug independently.
But separate processes create a new problem: how do you get data out of the database process and into the downstream consumers with minimal latency? That’s what this post is about.
Why Shared Memory
When two separate processes need to exchange data on the same machine, they use inter-process communication (IPC) — a set of mechanisms provided by the operating system for passing data across process boundaries. There are several ways:
| Method | Mechanism | Syscall per msg | Typical latency |
|---|---|---|---|
| TCP loopback | Full network stack | Yes | ~5–10 µs |
| Unix domain socket | Kernel buffer copy | Yes | ~1–5 µs |
| Pipe / Named pipe | Kernel buffer copy | Yes | ~1–5 µs |
| process_vm_writev | Direct cross-process write | Yes | ~200–500 ns |
| Shared memory | Direct memory access | No | ~50–100 ns |
Approximate ranges for small messages on modern Linux. Actual numbers vary with hardware, kernel version, and message size.
All kernel-mediated methods — sockets, pipes, message queues — require at least one system call per message. A syscall means a context switch from user space to kernel space and back, which alone costs hundreds of nanoseconds. For a system streaming thousands of updates per second, this overhead adds up. Call it stubbornness, but if I know there’s a faster way to do something, I can’t bring myself to settle for the slower one.
That faster way is shared memory. After a one-time mmap call at startup, both processes read and write the same physical RAM — no kernel involvement, no copies, no syscalls on the hot path. It’s the only IPC mechanism where the cost of sending a message is the same as writing to your own memory.
Several benchmarks confirm this hierarchy. Baeldung’s IPC comparison measured throughput across pipes, sockets, and named pipes. A Rust-specific ping-pong benchmark found that shared memory was the only approach that delivered sub-microsecond round trips, concluding that “for the cases where latency really matters, the maintenance overhead of using shared memory is worth it.” Bryan Lee’s UNIX IPC benchmarks showed shared memory outperforming all other methods because it avoids the kernel copy path entirely.
The trade-off is complexity — you have to build your own data structure on top. For my use case — one producer, multiple consumers, small fixed-size messages, same machine — that complexity is manageable and the latency gain is worth it. There’s one harder problem though: what happens when a consumer starts up and needs the full state, not just the last few messages in the ring? We’ll get to that.
How Shared Memory Works
By default, each process has its own private virtual address space — memory in one process is invisible to another. Shared memory breaks this isolation by mapping the same region of physical RAM into multiple processes’ address spaces.
On Linux, the simplest way to set this up is through /dev/shm, a RAM-backed tmpfs filesystem. The producer creates a file there, maps it into its address space with mmap, and writes data to it. The consumer opens the same file and maps it into its own address space. Both processes now see the same physical bytes — writes from one are immediately visible to the other.
1
2
3
4
Process A virtual memory Physical RAM Process B virtual memory
| | |
0x7fff1000 ───────────> 0x12340000 <─────── 0x7fff5000
| | |
No data is copied. No kernel is involved after the initial mmap. The file never touches disk — /dev/shm lives entirely in RAM. When the last process unmaps, the memory is freed.
The catch: shared memory gives you raw bytes. There’s no ordering, no notification when new data arrives, no protection against concurrent access. You need to build your own data structure on top — which is exactly what a ring buffer is for.
Building the Ring Buffer
A ring buffer is a fixed-size array that wraps around — the producer writes at the head, the consumer reads at the tail, and both indices loop back to the start when they reach the end. It’s the natural data structure for streaming: bounded memory, no allocation, predictable performance.
The Layout
1
2
3
4
5
6
7
8
9
const IPC_CAPACITY: usize = 4096;
const IPC_MASK: usize = IPC_CAPACITY - 1;
#[repr(C, align(64))]
pub struct SharedRing {
head: AtomicUsize,
_pad1: [u8; 56],
buffer: [Message; IPC_CAPACITY],
}
A few things to unpack here:
repr(C) locks the field order. Without it, Rust can rearrange fields for smaller memory footprint. With shared memory, both processes must agree on the exact byte offset of every field — repr(C) guarantees fields are laid out in declaration order.
align(64) tells the compiler to place this struct at a memory address divisible by 64. Combined with the 56-byte padding, this ensures head occupies its own cache line — starting at the beginning of one, not landing in the middle.
_pad1: [u8; 56] is 56 bytes of dead space. Why? CPU caches operate in 64-byte chunks called cache lines. AtomicUsize is 8 bytes, plus 56 bytes of padding equals exactly one cache line. Without this padding, head and the start of buffer would share the same cache line. Every time the producer updates head, the CPU would invalidate the cache line for the consumer too — even though the consumer doesn’t care about head yet. This is called false sharing, and it quietly destroys performance.
IPC_CAPACITY is a power of two so we can replace the expensive modulo operation (index % CAPACITY) with a fast bitmask (index & MASK). With 4096 slots, the mask is 0xFFF — a single bitwise AND instead of a division.
The ring message:
1
2
3
4
5
6
#[repr(C)]
#[derive(Copy, Clone)]
pub struct Message {
pub key: u64,
pub val: u64,
}
In production, keys and values are compacted into u64 pairs — a 32-byte Solana pubkey gets hashed down to 8 bytes. This shrinks each message from 64 bytes to 16, which means more messages per cache line and a larger effective ring capacity. I’ll cover the compaction scheme and its collision trade-offs in a future post.
A Note on Unsafe
From this point on, the code uses unsafe blocks. Shared memory is inherently outside Rust’s ownership model: two separate processes access the same bytes with no compiler-enforced borrow checking. There’s no way to express this in safe Rust, so unsafe is required — meaning we take on the responsibility of upholding the invariants the compiler normally enforces. Get them wrong, and the result is undefined behavior, not a compile error.
The contract we uphold manually: only one producer writes to head and the buffer, consumers only read. As long as this holds, the code is sound.
Writing: Push with Overwrite
1
2
3
4
5
6
7
8
pub fn push(&self, msg: Message) {
let head = self.head.load(Ordering::Relaxed);
unsafe {
let slot = &mut (*self.as_ptr()).buffer[head & IPC_MASK];
*slot = msg;
}
self.head.store(head.wrapping_add(1), Ordering::Release);
}
The producer doesn’t check whether the consumer has read the old data. If the consumer falls behind, the oldest messages get silently overwritten. This is intentional — in a real-time system, stale data is worse than no data. The consumer will detect the gap and skip forward.
Ordering::Relaxed on the head load: the producer is the only writer, so it always sees its own latest value. No synchronization needed for this read.
Ordering::Release on the head store: this is the critical part. Release ordering guarantees that the message write (*slot = msg) is visible to other processes before they see the updated head. Without this, a consumer could see a new head value but read garbage from the buffer — the CPU might reorder the store to head before the store to buffer.
wrapping_add(1) instead of += 1: the head index grows forever and wraps around naturally at usize::MAX. Combined with the bitmask, this means we never need to reset the counter.
Reading: Pop with Catch-Up
The consumer tracks its own tail locally — not in shared memory:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct Consumer {
ring: *const SharedRing,
tail: usize,
}
impl Consumer {
fn pop(&mut self) -> Option<Message> {
let head = unsafe { &*self.ring }.head.load(Ordering::Acquire);
if head == self.tail { return None; }
let diff = head.wrapping_sub(self.tail);
if diff > IPC_CAPACITY {
// producer lapped us — skip to oldest valid data
self.tail = head.wrapping_sub(IPC_CAPACITY);
}
let data = unsafe { (*self.ring).buffer[self.tail & IPC_MASK] };
self.tail = self.tail.wrapping_add(1);
Some(data)
}
}
Ordering::Acquire on the head load pairs with the producer’s Release store. This guarantees: if the consumer sees head = N, then all buffer writes up to slot N are also visible. Acquire and Release form a synchronization contract — Release publishes data, Acquire subscribes to it.
The catch-up logic: if head - tail > CAPACITY, the producer has lapped the consumer. The oldest data in the buffer has been overwritten. Rather than reading corrupt data, the consumer jumps its tail forward to the oldest valid slot. The consumer can detect exactly how many messages were lost: diff - IPC_CAPACITY.
tail is local, not atomic: only the consumer reads and writes it. No other process touches it. This means zero synchronization overhead on the read path — just a plain usize increment.
Why This Is Fast
On x86, Acquire and Release compile down to plain mov instructions — the CPU’s strong memory model provides these guarantees for free. The only real cost is preventing the compiler from reordering stores, which has no runtime overhead.
On ARM, the story is different. Release stores emit a stlr instruction and Acquire loads emit a ldar — both carry a small penalty compared to plain loads and stores, typically adding 5–20ns depending on the core and contention. The ring buffer still works correctly, but your p50 will be higher than on x86. If you’re deploying on ARM, benchmark there — don’t extrapolate from x86 numbers.
In Practice
I ran the producer and consumer on an AMD Ryzen 9 9900X (12 cores / 24 threads), measured with the quanta crate (rdtsc-based, calibrated to wall-clock nanoseconds at startup, ~10ns resolution on this chip). Results over 10K message batches.
Same CCX (cores 10 and 11 — separate physical cores, shared L3):
1
2
3
4
5
6
7
8
9
10
[round 1] avg: 61 ns | min: 30 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 2] avg: 61 ns | min: 30 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 3] avg: 61 ns | min: 30 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 4] avg: 61 ns | min: 40 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 5] avg: 61 ns | min: 50 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 6] avg: 61 ns | min: 40 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 7] avg: 62 ns | min: 40 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 8] avg: 61 ns | min: 40 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 9] avg: 61 ns | min: 30 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
[round 10] avg: 62 ns | min: 50 ns | p50: 60 ns | p90: 70 ns | p99: 80 ns | lost: 0
~60ns p50, remarkably stable across rounds. The tight spread between p50 and p99 (20ns) tells us there’s almost no jitter — the hot path is hitting L3 consistently with no contention.
Cross-CCX (cores 10 and 17 — separate physical cores, separate L3 groups):
1
2
3
4
5
6
7
8
9
10
[round 1] avg: 193 ns | min: 180 ns | p50: 190 ns | p90: 200 ns | p99: 220 ns | lost: 0
[round 2] avg: 194 ns | min: 180 ns | p50: 190 ns | p90: 200 ns | p99: 230 ns | lost: 0
[round 3] avg: 197 ns | min: 150 ns | p50: 190 ns | p90: 200 ns | p99: 350 ns | lost: 0
[round 4] avg: 198 ns | min: 180 ns | p50: 200 ns | p90: 210 ns | p99: 360 ns | lost: 0
[round 5] avg: 197 ns | min: 180 ns | p50: 190 ns | p90: 200 ns | p99: 280 ns | lost: 0
[round 6] avg: 197 ns | min: 180 ns | p50: 190 ns | p90: 200 ns | p99: 360 ns | lost: 0
[round 7] avg: 196 ns | min: 150 ns | p50: 190 ns | p90: 200 ns | p99: 220 ns | lost: 0
[round 8] avg: 198 ns | min: 150 ns | p50: 190 ns | p90: 200 ns | p99: 360 ns | lost: 0
[round 9] avg: 198 ns | min: 70 ns | p50: 190 ns | p90: 200 ns | p99: 360 ns | lost: 0
[round 10] avg: 195 ns | min: 70 ns | p50: 190 ns | p90: 200 ns | p99: 220 ns | lost: 0
Cross-CCX triples the p50 to ~190ns. The head cache line now travels between L3 slices via the Infinity Fabric interconnect instead of being shared directly. The p99 also becomes spikier (up to 360ns), likely from occasional Infinity Fabric contention. Still sub-microsecond, still faster than any kernel-mediated IPC — but the topology matters. Pin your producer and consumers to the same CCX if you can.
The full source code is available at github.com/bangnbx/shared-mem-demo — a minimal working example you can run on any Linux machine.
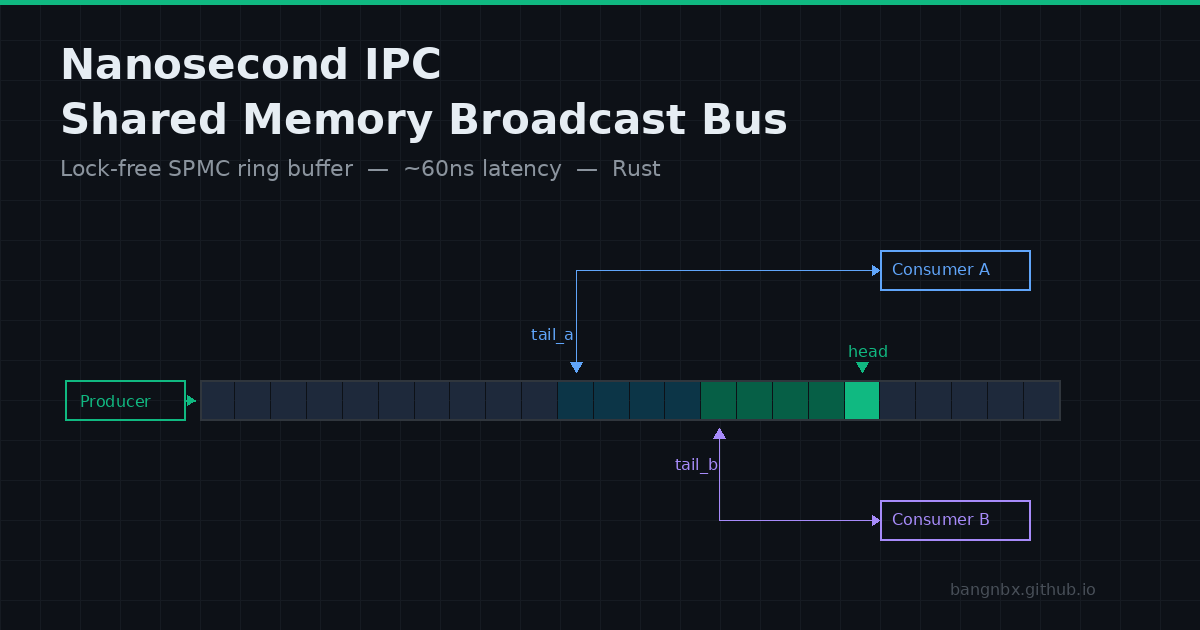
Extending to SPMC Broadcast
So far we have one producer and one consumer. But what if multiple downstream processes need the same data — a logger, an analytics pipeline, an arbitrage engine?
One option is to create a separate ring buffer for each consumer and have the producer write to all of them. This works but duplicates every write — N consumers means N memcpys per message.
A better approach: broadcast. The producer writes each message once. Every consumer reads from the same buffer independently. This works because our ring buffer already has the right shape — the producer only writes to head and the buffer, consumers only read. There’s no shared mutable state between consumers.
Since each consumer already tracks tail locally, adding more consumers requires no changes to the ring buffer or the producer. Consumer A might be at tail 500, Consumer B at tail 450, Consumer C just started at tail 1000. Each advances independently. The producer doesn’t know or care how many consumers exist — it just writes to head and moves on.
This is nearly zero-contention by design. Consumers never write to shared memory. They never coordinate with each other. The only shared state they read is head, and on x86 a read of an atomic is a plain mov — no bus lock, no cache-line bouncing from the readers themselves. The only contention is between the producer and consumers: every time the producer updates head, it invalidates that cache line on every consumer core. Each consumer has to re-fetch the line — typically from L3, which is cheap (single-digit nanoseconds). With a handful of consumers, this barely registers. At higher fan-out the cost scales linearly — N consumers means N re-fetches per write — but it still dwarfs any lock-based alternative.
Since consumers never write to shared memory, they can map the file as read-only (PROT_READ) — the kernel will kill any consumer that accidentally writes, enforcing the contract at the OS level.
What about slow consumers?
If a consumer falls too far behind, the producer overwrites its unread data. The consumer detects this when head - tail > CAPACITY and skips forward to the oldest valid slot. Each consumer handles this independently — a slow logger doesn’t affect a fast trading engine.
SPMC Benchmark
Producer on core 10, three consumers: cores 11 and 20 (same CCX), core 17 (cross-CCX). Same producer, same publication rate, same 10K batch size as the SPSC benchmark — only the number of consumers changed.
| Consumer | CCX | p50 | p90 | p99 |
|---|---|---|---|---|
| Core 11 | Same | 150 ns | 160 ns | 230 ns |
| Core 20 | Same | 140 ns | 160 ns | 230 ns |
| Core 17 | Cross | 210 ns | 220 ns | 270 ns |
Adding consumers isn’t free — same-CCX p50 rose from 60ns (one consumer) to ~150ns (three consumers). Each additional reader increases invalidation traffic on the head cache line, and the producer’s store must propagate to more cores. But consumers remain independent: the cross-CCX consumer’s higher latency doesn’t slow down the same-CCX pair, and no consumer coordinates with any other.
Bootstrapping the Consumer
The ring buffer only holds the last CAPACITY messages. When a consumer starts — or restarts after a crash — it needs the full current state, not just recent updates. The solution is a two-phase handshake between producer and consumer.
The canonical data lives in RocksDB, but I maintain a separate flat file optimized for fast sequential reads. Each record is a fixed 16 bytes (two u64 fields), so the consumer can read the entire file in a single sequential scan with no parsing — just stride through memory 16 bytes at a time. This file only needs to support bulk loading, not random lookups, so it can use a more compact representation than RocksDB. Reading a flat binary file is significantly faster than iterating over RocksDB’s SST files.
The producer always writes every update to this file before pushing it to the ring buffer. This ordering is critical — it guarantees that anything missing from the ring already exists in the file.
When a consumer connects, the protocol is:
- Clear and consume — the consumer sets its tail to the current head and immediately starts consuming from the ring. New messages are processed in real time from this point forward.
- Request flush — next, the consumer sets a
flush_requestflag in shared memory. - Wait — the producer sees the flag, calls
sync_all()on the file, then signals completion. - Read file — the consumer reads the file to load the full baseline state, merging it with any messages already received from the ring.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Producer: write to file first, then ring
file.write(&data)?;
ring.push(msg);
// Producer: check flush request each iteration
if ring.flush_requested() {
file.sync_all()?;
ring.complete_flush();
}
// Consumer: startup sequence
consumer.skip_to_head(); // advance tail to current head
// start processing ring immediately in background
ring.request_flush(); // ask producer to sync file
while !ring.flush_complete() {
std::hint::spin_loop();
}
let state = load_from_file("state.bin");
Why this is gap-free: anything written before skip_to_head() is in the file (because file-write happens before ring-push). Anything written after skip_to_head() is in the ring and already being consumed. The consumer gets both.
We traced one edge case during development: if the consumer calls skip_to_head() between the producer’s file write and ring push, that specific message appears in the file but not in the ring. This is harmless — the consumer picks it up from the file after flush. The file-first write order guarantees no message is ever lost.
Shared Memory and Trust
Shared memory has no built-in access control beyond filesystem permissions — any process running as the same user can open /dev/shm/your_file. This isn’t unique to shared memory; Unix domain sockets and named pipes have the same model. For a system where you control all processes on a dedicated server, chmod 600 on the shm file is sufficient.
Takeaways
- Shared memory is the fastest local IPC. Once mapped, it’s just memory access — no syscalls, no copies, no kernel on the hot path. Our ring buffer delivers ~60ns p50 on the same CCX, confirmed by measurement.
- Pin to the same CCX. Cross-CCX communication tripled latency in our benchmarks (60ns → 190ns). Shared L3 is what makes this fast — if your producer and consumers span CCXs or NUMA nodes, you’re paying for interconnect on every message.
- SPMC broadcast scales without coordination. Moving the tail out of shared memory and into each consumer means adding consumers requires zero changes to the producer or the ring buffer. More consumers do increase cache-line invalidation traffic — same-CCX p50 rose from 60ns to 150ns with three readers — but consumers remain fully independent: a slow one never blocks a fast one.
- Test on real hardware. Cache-line effects, memory ordering, and TSC behavior are CPU-dependent. Numbers from one machine don’t transfer to another — always benchmark your own deployment.
- Overwrite, don’t block. For real-time data, stale messages are worse than dropped messages. Let slow consumers detect the gap and skip forward.